摘要:Flink是一个针对流数据、批数据进行处理的分布式处理引擎,可以处理有界限的数据、无界限的数据。在Flink的架构中包含四层,分别是Deploy部署层、Core核心层、API接口层、Lib扩展库层。
2020年天猫双十一全球狂欢季成交额4982亿元人民币。在那年的整个双十一中,我们通过Dashboard实时数据大盘可以知道每分钟的成交额、订单数、爆款商品、爆款售卖地区等等,这个Dashboard背后的技术便是数据实时计算和流式计算。
所谓实时计算指的是实时可以获取到想要的数据,比如我想查询我今年双十一的购买额,输入姓名、时间后立即可以统计出数据,所谓流式计算指的是我每买一件东西,购买量自动加1,订单额自动增加。实时计算和流式计算都是相对离线计算的改善,离线计算有一定的延迟,它把数据从存储中取出来,进行统计,最后再呈现。
我们在双十一成交额大盘所看到的便是实时计算与流式计算的结合,实现流式计算的技术有很多,比如storm、spark、flink,而这其中最流行、使用最广的便是flink,接下来我们就一起来看看flink到底是什么技术?

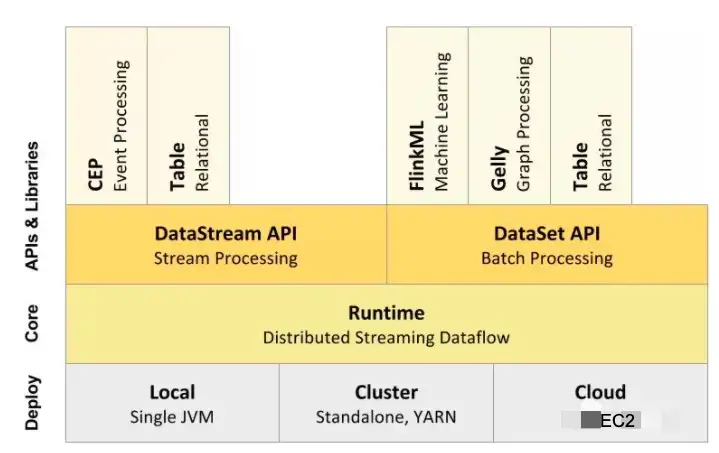
Flink是一个针对流数据、批数据进行处理的分布式处理引擎,可以处理有界限的数据(数据量有限,不会改变的数据集合,比如双十一当天数据量)、无界限的数据(比如淘宝用户产生的实时交互数据、股票市场的实时交易记录)。在Flink的架构中包含四层,分别是Deploy部署层、Core核心层、API接口层、Lib扩展库层。
在部署层主要是Flink的部署模式,它支持Local本地化部署,直接在IDE代码编辑器中就可以运行程序;也支持集群化部署,在Kubernetes或使用Hadoop的Yarn来做集群调度;也支持云上部署,通过弹性主机实现自动扩缩容。在Core核心层,主要是分布式流式处理引擎,支持分布式stream处理,支持jobgraph到execution的映射调度,支持上层API接口的任务。在API层主要是提供API给到开发者编写分布式任务,包含DataSetAPI、DataStreamAPI两类API,DataStreamAPI主要用于对流数据进行处理,它可以将流式数据抽象成分布式的数据流,开发者就很方便的对分布式数据流进行操作处理,DataSetAPI主要对于数据进行批量处理,将静态的、有限的数据抽象成分布式的数据集处理。在Lib扩展库层主要是通过扩展库方式提供更多使用场景给到开发者,比如CEP复杂事件处理、Table把结构化数据抽象成关系表,并支持类SQL语句查询、FlinkML支持机器学习、Gelly图计算库支持图处理。
了解完Flink的基础框架之后,我们再来看看Flink的基本编程模型是怎么样的?在Flink中主要是三个步骤,数据源进行数据输入、数据转换、数据输出,开发者可以把数据库的数据或自己本地文件数据或消息队列Kafka的数据通过API接口传递给到Flink,Flink处理引擎将数据转化成按时间窗口排序或按最热门排序或按地区聚合等数据,最后再通过Sink将数据输出到消息队列或数据大盘中进行展示。

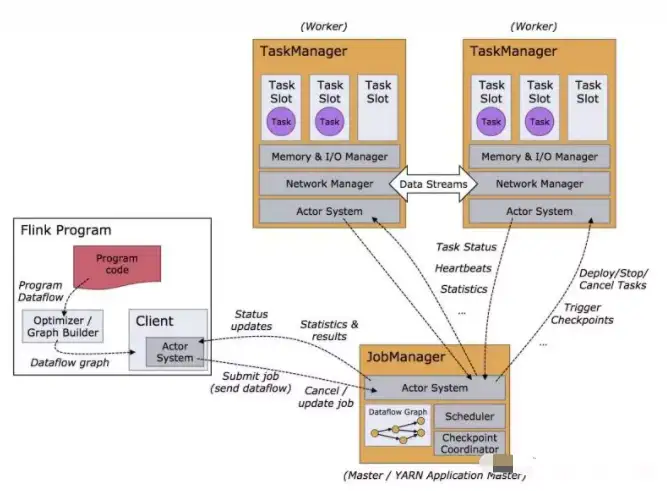
在Flink的处理引擎中,数据是这样进行流转,开发者编写Flink应用程序代码,通过Client传递给到JobManager,JobManager是Flink的Master节点,负责安排任务给到TaskManager去执行,同时管理TaskManager节点的调度情况,如果忙不过来或者故障,再把任务分配给到其它的TaskManager。TaskManager主要负责接收来自JobManager的任务,一个TaskManager占据一个JVM内存,在TaskManager中还包含TaskSlot的概念,用于内存分配管理,一个Slot代表为其分配100%的内存空间,两个则代表为每个分配50%的空间,每个Slot占据1个线程来具体的执行任务。
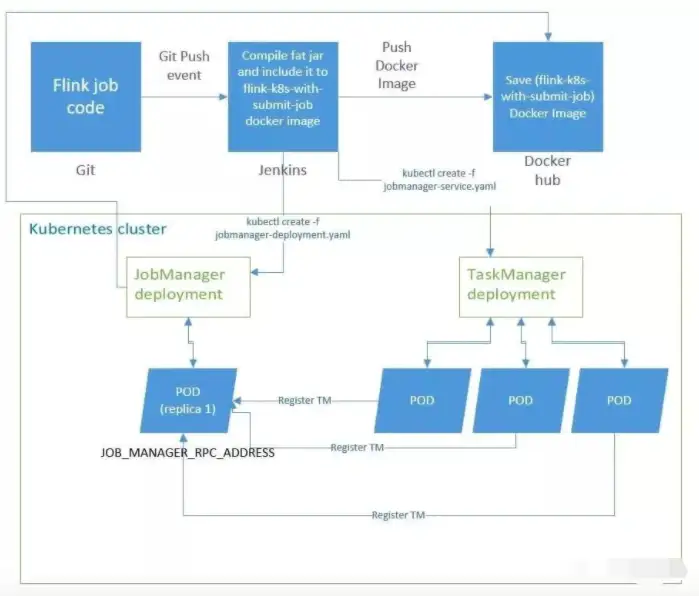
在DevOps工程师文化、Kubernetes容器技术盛行的互联网,Flink也可以联同二者进行工作,尤其是在大厂,基本都是这样的架构运行原理。开发人员编写好Flink任务代码,通过Git的push事件进行代码提交,同时触发了对应的Jenkins集群,在Kubernetes中进行JobManager、TaskManager的部署,JobManager和TaskManager占据一个或多个POD,实现了自动弹性伸缩,开发者或运维人员基于Kubernetes还可以调度管理Flink系统。
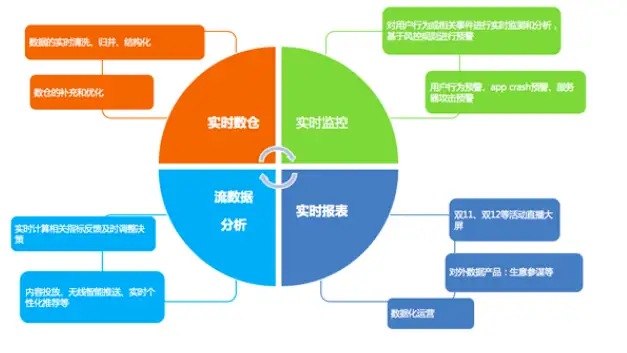
本文介绍了Flink的基本架构、编程模型、运行原理,它还有很多应用场景。我们抽象的从三个维度来看:
1、基于事件驱动,开发者将采集的事件不断放入消息队列,Flink不断的进行消息队列数据消费,每消费一条数据,则触发一个动作,在欺诈检测、异常检测、基于规则的告警、业务流程监控中都可以使用Flink的这个特性;
2、分析场景,开发者将数据实时或周期性的写入消息队列,Flink不断的将应用源数据做实时计算,不断更新数据库或HDFS,最后做大屏展示或数据报表,比如双十一的DashBoard;
3、管道式ETL,即提取数据放到数据库或文件系统当中。下图是Flink在阿里巴巴内部的主要应用场景。
除了阿里之外,在百度、腾讯、美团、滴滴、头条、京东、拼多多等公司,Flink的应用也是非常普及的。在互联网流量为王时代,基于大数据去做离线分析、实时分析是必不可少的,数据开发工程师的薪酬也非常可人,掌握Flink基础使用知识也是必备技能,如果你对大数据开发感兴趣,那么赶快学习上车Flink吧~